http://www.nostops.org
http://arunvakil4usvisas.com
Sunday, November 27, 2005
Thursday, November 24, 2005
Friday, November 18, 2005
ASP.NET Questions
1) How security is implemented in asp.net
ASP.NET implement security in three ways
a- Forms-based security
in this case you set the IIS authentication system to anonymous access to enable the ASP.NET to validate authentication itself by checking if the user name & Password is equivalent to the same info which is stored anyhow (XML, Database, ...)
b- Windows-based security
according to this option any user access the site must have a registered windows account and a dedicated permissions
Passport-based security
this is a centric authentication service in which one login could auto authenticate the user for many sites where is no need to store the user names & passwords into each site
all what you have to do is to creat a folder then move your required files into it then configur the web.config as follows :
// or you can write your pages names instead of folder name
it is the auto generated default view of the table in the dataset , when dealing with any table in a dataset, .NET makes a view of that table to can communicate with it so it is the default one
they all do the same functions except the stored functions can return a table and can be implemented into a select statement like " select myFunction(someParam)"
You can use session variables to store this a.aspx textBoxs Like session ["myVar"]=TextBox1.Txt
the datagrid is designed to show a table-like data to the user but the datalist is designed to show a row-like data
ASP.NET implement security in three ways
a- Forms-based security
in this case you set the IIS authentication system to anonymous access to enable the ASP.NET to validate authentication itself by checking if the user name & Password is equivalent to the same info which is stored anyhow (XML, Database, ...)
b- Windows-based security
according to this option any user access the site must have a registered windows account and a dedicated permissions
Passport-based security
this is a centric authentication service in which one login could auto authenticate the user for many sites where is no need to store the user names & passwords into each site
2) In my website for eg. it has around 100 aspx. In that I want 20 aspx files should be available to the users only if they are logged in. How can I achieve this with web.config file.
all what you have to do is to creat a folder then move your required files into it then configur the web.config as follows :
What do you meant by default view
it is the auto generated default view of the table in the dataset , when dealing with any table in a dataset, .NET makes a view of that table to can communicate with it so it is the default one
Difference between stored procedure and stored functions
they all do the same functions except the stored functions can return a table and can be implemented into a select statement like " select myFunction(someParam)"
5) I have a file called a.aspx which has some textboxes. I want to post the values to b.aspx without using response.redirect. How can I do this.
You can use session variables to store this a.aspx textBoxs Like session ["myVar"]=TextBox1.Txt
Different between datagrid and datalist
the datagrid is designed to show a table-like data to the user but the datalist is designed to show a row-like data
Monday, November 14, 2005
Improving Web Service Performance : CheckList
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnpag/html/scalenetcheck09.asp
All about Installers - Customizing Windows and Web setup projects
http://www.codeproject.com/dotnet/CustomizingInstallers.asp
Wednesday, October 05, 2005
String Vs String Builder
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dndotnet/html/vbnstrcatn.asp
Tuesday, September 20, 2005
Microsoft .NET Framework FAQ
FAQ's on .NET Framework from Microsoft !!
http://msdn.microsoft.com/library/default.asp?url=/library/en-
us/dndotnet/html/faq111700.asp
Keep watching this blog !!!
http://msdn.microsoft.com/library/default.asp?url=/library/en-
us/dndotnet/html/faq111700.asp
Keep watching this blog !!!
Monday, July 18, 2005
String.Contains + Some Other String Improvements in VS2005
There's some things just so glaringly obvious, so innately presupposed that you just assume it's there and it's an impossible task to convince your brain otherwise.
For me, this is string.Contains. For years I've typed "name.Conta…" only to stop and realize that it's not there. I begrudgingly type in "name.IndexOf("sdfsd")>-1" instead. The next time I do the same. In fact I've been using .Net since it was in early beta and yet I still haven't come to terms with the fact string.Contains is missing.
Then today, working in VS 2005, I once again accidentally type it in - and to my disbelief it's actually there! Very cool.
Couple of other things I noticed:
1. String.Split now accepts strings. That means you can split a string like “bob and harry and mary and jane“ on “and“ and you'll get just the people names.
2. String.NullOrEmpty is a new static method that returns true if the string is null or empty (““). All those times I've used code like “if (name==null || name==““) “...
That's what I call progress.
For me, this is string.Contains. For years I've typed "name.Conta…" only to stop and realize that it's not there. I begrudgingly type in "name.IndexOf("sdfsd")>-1" instead. The next time I do the same. In fact I've been using .Net since it was in early beta and yet I still haven't come to terms with the fact string.Contains is missing.
Then today, working in VS 2005, I once again accidentally type it in - and to my disbelief it's actually there! Very cool.
Couple of other things I noticed:
1. String.Split now accepts strings. That means you can split a string like “bob and harry and mary and jane“ on “and“ and you'll get just the people names.
2. String.NullOrEmpty is a new static method that returns true if the string is null or empty (““). All those times I've used code like “if (name==null || name==““) “...
That's what I call progress.
C# source code line counter and a .net complexity analyzer (using the cyclomatic complexity index !!
http://dotnetjunkies.com/WebLog/johnwood/archive/2005/01/16/44995.aspx
Friday, July 08, 2005
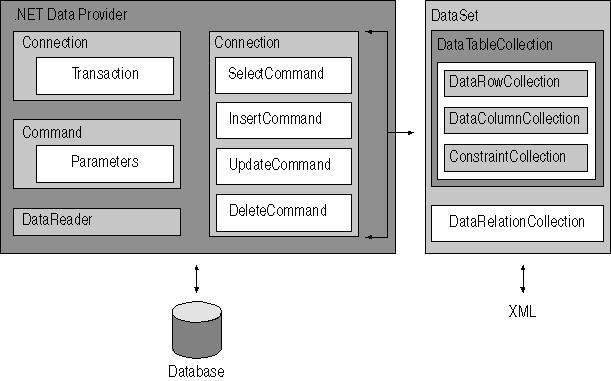
Difference b/w ADO and ADO.NET
Differences Between ADO and ADO.NET
ADO and ADO.NET have various differences, such as differences in architecture, data representation, and methods of sharing data between applications.
In-Memory Representations of Data
ADO uses a recordset to represent data that is retrieved from tables in memory, whereas ADO.NET uses DataSets. A recordset usually contains data from a single table. To store data from multiple tables, you use a JOIN query. The JOIN query retrieves the data from multiple tables as a single result table. Alternatively, ADO.NET uses a DataSet to represent data in memory. As mentioned earlier, a DataSet can store data from multiple tables and multiple sources. In addition, a DataSet can also contain relationships between tables and the constraints on a table. Therefore, a DataSet can represent the structure of a database.
ADO provides a read-only navigation on recordsets, which allows you to navigate sequentially through the rows of the recordset. However, in ADO.NET, rows are represented as collections. Therefore, you can access records using the primary key index. In addition, you can also filter and sort results.
Minimized Open Connections
In ADO.NET, you only connect to a database to retrieve and update records. You can retrieve records from a database, copy them into a DataSet, and then disconnect from the database. Although a recordset can provide disconnected data access in ADO, ADO was primarily designed for connected scenarios.
In ADO.NET, you communicate with the database using a DataAdapter or a DataReader that makes calls to an OLE DB provider or to the APIs provided by the data source.
Sharing Data Between Applications
You use COM marshaling in ADO to transfer a disconnected recordset from one component to another. In ADO.NET, you transfer a DataSet using an XML stream. XML provides the following advantages over COM marshaling when transferring data:
Richer data types.
COM marshaling can only convert data types that are defined by the COM standard. In an XML-based data transfer, restrictions on data types do not exist. You can use XML-based data transfer to transfer any data that is serializable.
Bypassing firewalls.
A firewall does not allow system-level requests, such as COM marshaling. Therefore, a recordset cannot bypass a firewall. However, because firewalls allow HTML text to pass and ADO.NET uses XML to transfer DataSets, you can send an ADO.NET DataSet through a firewall.
ADO and ADO.NET have various differences, such as differences in architecture, data representation, and methods of sharing data between applications.
In-Memory Representations of Data
ADO uses a recordset to represent data that is retrieved from tables in memory, whereas ADO.NET uses DataSets. A recordset usually contains data from a single table. To store data from multiple tables, you use a JOIN query. The JOIN query retrieves the data from multiple tables as a single result table. Alternatively, ADO.NET uses a DataSet to represent data in memory. As mentioned earlier, a DataSet can store data from multiple tables and multiple sources. In addition, a DataSet can also contain relationships between tables and the constraints on a table. Therefore, a DataSet can represent the structure of a database.
ADO provides a read-only navigation on recordsets, which allows you to navigate sequentially through the rows of the recordset. However, in ADO.NET, rows are represented as collections. Therefore, you can access records using the primary key index. In addition, you can also filter and sort results.
Minimized Open Connections
In ADO.NET, you only connect to a database to retrieve and update records. You can retrieve records from a database, copy them into a DataSet, and then disconnect from the database. Although a recordset can provide disconnected data access in ADO, ADO was primarily designed for connected scenarios.
In ADO.NET, you communicate with the database using a DataAdapter or a DataReader that makes calls to an OLE DB provider or to the APIs provided by the data source.
Sharing Data Between Applications
You use COM marshaling in ADO to transfer a disconnected recordset from one component to another. In ADO.NET, you transfer a DataSet using an XML stream. XML provides the following advantages over COM marshaling when transferring data:
Richer data types.
COM marshaling can only convert data types that are defined by the COM standard. In an XML-based data transfer, restrictions on data types do not exist. You can use XML-based data transfer to transfer any data that is serializable.
Bypassing firewalls.
A firewall does not allow system-level requests, such as COM marshaling. Therefore, a recordset cannot bypass a firewall. However, because firewalls allow HTML text to pass and ADO.NET uses XML to transfer DataSets, you can send an ADO.NET DataSet through a firewall.
Sunday, July 03, 2005
MCAD Curriculum !! .NET Certification
http://www.msnusers.com/dotnetusergroupHyd/Documents/MCAD/GetCertified%2Edoc?t=6Kbmod!HwFS0cCqORc8q11L5ffL*Rgh8f!XhiuOL5BB5!ik*Ro6u4WvoplAjaTP0*duXGQlZyo2UiuTK9lnkigQOrB5EiK2d5S1DG2WEV5Gk*It2xRjMZu*Q$$&p=6sZOl*PNwCl8lUVzZe6fwS6hNIjkz1cq*HOUvKatry5phELqQ4YIGWZxBg6f3*ABmUkT!aWxS0TFcJ8SzbVsL32hpqNf7ARLqJo6NWGlKimTQ95lffwpFlboXNti05MqiL1Q473Tee1ltXhX058BWv7ovuczKUEpaUn07F1kntUUCd30RpQf!0GQ$$
Tuesday, June 14, 2005
Total ASP.NET Security (Complete Concepts !!)
http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnnetsec/html/SecNetch08.asp
Friday, June 03, 2005
How to Convert Integer to Binary
The Convert class has an overload of the static ToString() method that takes two ints and returns a string populated with the number in the specified base. For instance, calling Convert.ToString(128, 2) will return "10000000".
Quick Tip
It is highly confusing to say that objects are passed by reference by default instead of the correct statement that "object references are passed by value by default".
Tuesday, May 31, 2005
Monday, May 02, 2005
Tuesday, April 26, 2005
Boxing and Unboxing
There are many situations in which it is convenient to treat a value type as a reference type. Let's say that you wanted to create an ArrayList object (a type defined in the System.Collections namespace) to hold a set of Points. The code might look like Figure 3.
With each iteration of the loop, a Point value type is initialized. Then, the Point is stored in the ArrayList. But let's think about this for a moment. What is actually being stored in the ArrayList? Is it the Point structure, the address of the Point structure, or something else entirely? To get the answer, you must look up the ArrayList's Add method and see what type its parameter is defined as. In this case, you see that the Add method is prototyped in the following manner:
public virtual void Add(Object value)
The previous code plainly shows that Add takes an Object as a parameter. Object always identifies a reference type. But here I'm passing p, which is a Point value type. For this code to work, the Point value type must be converted into a true heap-managed object, and a reference to this object must be obtained.
Converting a value type to a reference type is called boxing. Internally, here's what happens when a value type is boxed:
Memory is allocated from the heap. The amount of memory allocated is the size required by the value type plus any additional overhead to consider this value a true object. The additional overhead includes a pointer to a virtual method table and a pointer to a sync block.
The value type's bits are copied to the newly allocated heap memory.
The address of the object is returned. This address is now a reference type.
Some language compilers, like C#, automatically produce the IL code necessary to box the value type, but it is important that you understand what's going on under the covers so that you are aware of code size and performance issues.
When the Add method is called, memory is allocated in the heap for a Point object. The members currently residing in the Point value type (p) are copied into the newly allocated Point object. The address of the Point object (a reference type) is returned and is then passed to the Add method. The Point object will remain in the heap until it is garbage-collected. The Point value type variable (p) can be reused or freed since the ArrayList never knows anything about it. Boxing enables a unified view of the type system, where a value of any type can ultimately be treated as an object.
The opposite of boxing is, of course, unboxing. Unboxing retrieves a reference to the value type (data fields) contained within an object. Internally, the following is what happens when a reference type is unboxed:
The common language runtime first ensures that the reference type variable is not null and that it refers to an object that is a boxed value of the desired value type. If either test fails, then an InvalidCastException exception is generated.
If the types do match, then a pointer to the value type contained inside the object is returned. The value type that this pointer refers to does not include the usual overhead associated with a true object: a pointer to a virtual method table and a sync block.
Note that boxing always creates a new object and copies the unboxed value's bits to the object. On the other hand, unboxing simply returns a pointer to the data within a boxed object: no memory copy occurs. However, it is commonly the case that your code will cause the data pointed to by the unboxed reference to be copied anyway.
The following code demonstrates boxing and unboxing:
public static void Main() {
Int32 v = 5; // Create an unboxed value type variable
Object o = v; // o refers to a boxed version of v
v = 123; // Changes the unboxed value to 123
Console.WriteLine(v + ", " + (Int32) o); // Displays "123, 5"
}
From this code, can you guess how many boxing operations occur? You might be surprised to discover that the answer is three! Let's analyze the code carefully to really understand what's going on.
First, an Int32 unboxed value type (v) is created and initialized to 5. Then an Object reference type (o) is created and it wants to point to v. But reference types must always point to objects in the heap, so C# generated the proper IL code to box v and stored the address of the boxed version of v in o. Now 123 is unboxed and the referenced data is copied into the unboxed value type v; this has no effect on the boxed version of v, so the boxed version keeps its value of 5. Note that this example shows how o is unboxed (which returns a pointer to the data in o), and then the data in o is memory copied to the unboxed value type v.
Now, you have the call to WriteLine. WriteLine wants a String object passed to it but you don't have a String object. Instead, you have these three items: an Int32 unboxed value type (v), a string, and an Int32 reference (or boxed) type (o). These must somehow be combined to create a String.
To accomplish this, the C# compiler generates code that calls the String object's static Concat method. There are several overloaded versions of Concat. All of them perform identically; the difference is in the number of parameters. Since you want to format a string from three items, the compiler chooses the following version of the Concat method:
public static String Concat(Object arg0, Object arg1, Object arg2);
For the first parameter, arg0, v is passed. But v is an unboxed value parameter and arg0 is an Object, so v must be boxed and the address to the boxed v is passed for arg0. For the arg1 parameter, the address of the ", " string is passed, identifying the address of a String object. Finally, for the arg2 parameter, o (a reference to an Object) was cast to an Int32. This creates a temporary Int32 value type that receives the unboxed version of the value currently referred to by o. This temporary Int32 value type must be boxed once again with the memory address being passed for Concat's arg2 parameter.
Once Concat is called, it calls each of the specified object's ToString methods and concatenates each object's string representation. The String object returned from Concat is then passed to WriteLine to show the final result.
I should point out that the generated IL code would be more efficient if the call to WriteLine were written as follows:
Console.WriteLine(v + ", " + o); // Displays "123, 5"
This line is identical to the previous version except that I've removed the (Int32) cast that preceded the variable o. This code is more efficient because o is already a reference type to an Object and its address may simply be passed to the Concat method. So, removing the cast saved both an unbox and a box operation.
Here is another example that demonstrates boxing and unboxing:
public static void Main() {
Int32 v = 5; // Create an unboxed value type variable
Object o = v; // o refers to the boxed version of v
v = 123; // Changes the unboxed value type to 123
Console.WriteLine(v); // Displays "123"
v = (Int32) o; // Unboxes o into v
Console.WriteLine(v); // Displays "5"
}
How many boxing operations do you count in this code? The answer is one. There is only one boxing operation because there is a WriteLine method that accepts an Int32 as a parameter:
public static void WriteLine(Int32 value);
In the two calls to WriteLine, the variable v (an Int32 unboxed value type) is passed by value. Now, it may be that WriteLine will box this Int32 internally, but you have no control over that. The important thing is that you've done the best you could and have eliminated the boxing from your code.
If you know that the code you're writing is going to cause the compiler to generate a lot of boxing code, you will get smaller and faster code if you manually box value types, as shown in Figure 4.
The C# compiler automatically generates boxing and unboxing code. This makes programming easier, but it hides the overhead from the programmer who is concerned with performance. Like C#, other languages may also hide boxing or unboxing details. However, some languages may force the programmer to explicitly write boxing or unboxing code. For example, C++ with Managed Extensions requires that the programmer explicitly box value types using the __box operator; unboxing a value type is done by casting the boxed type to its unboxed equivalent using dynamic_cast.
One last note: if a value type doesn't override a virtual method defined by System.ValueType, then this method can only be called on the boxed form of the value type. This is because only the boxed form of the object has a pointer to a virtual method table. Methods defined directly with the value type can be called on boxed and unboxed versions of the value.
With each iteration of the loop, a Point value type is initialized. Then, the Point is stored in the ArrayList. But let's think about this for a moment. What is actually being stored in the ArrayList? Is it the Point structure, the address of the Point structure, or something else entirely? To get the answer, you must look up the ArrayList's Add method and see what type its parameter is defined as. In this case, you see that the Add method is prototyped in the following manner:
public virtual void Add(Object value)
The previous code plainly shows that Add takes an Object as a parameter. Object always identifies a reference type. But here I'm passing p, which is a Point value type. For this code to work, the Point value type must be converted into a true heap-managed object, and a reference to this object must be obtained.
Converting a value type to a reference type is called boxing. Internally, here's what happens when a value type is boxed:
Memory is allocated from the heap. The amount of memory allocated is the size required by the value type plus any additional overhead to consider this value a true object. The additional overhead includes a pointer to a virtual method table and a pointer to a sync block.
The value type's bits are copied to the newly allocated heap memory.
The address of the object is returned. This address is now a reference type.
Some language compilers, like C#, automatically produce the IL code necessary to box the value type, but it is important that you understand what's going on under the covers so that you are aware of code size and performance issues.
When the Add method is called, memory is allocated in the heap for a Point object. The members currently residing in the Point value type (p) are copied into the newly allocated Point object. The address of the Point object (a reference type) is returned and is then passed to the Add method. The Point object will remain in the heap until it is garbage-collected. The Point value type variable (p) can be reused or freed since the ArrayList never knows anything about it. Boxing enables a unified view of the type system, where a value of any type can ultimately be treated as an object.
The opposite of boxing is, of course, unboxing. Unboxing retrieves a reference to the value type (data fields) contained within an object. Internally, the following is what happens when a reference type is unboxed:
The common language runtime first ensures that the reference type variable is not null and that it refers to an object that is a boxed value of the desired value type. If either test fails, then an InvalidCastException exception is generated.
If the types do match, then a pointer to the value type contained inside the object is returned. The value type that this pointer refers to does not include the usual overhead associated with a true object: a pointer to a virtual method table and a sync block.
Note that boxing always creates a new object and copies the unboxed value's bits to the object. On the other hand, unboxing simply returns a pointer to the data within a boxed object: no memory copy occurs. However, it is commonly the case that your code will cause the data pointed to by the unboxed reference to be copied anyway.
The following code demonstrates boxing and unboxing:
public static void Main() {
Int32 v = 5; // Create an unboxed value type variable
Object o = v; // o refers to a boxed version of v
v = 123; // Changes the unboxed value to 123
Console.WriteLine(v + ", " + (Int32) o); // Displays "123, 5"
}
From this code, can you guess how many boxing operations occur? You might be surprised to discover that the answer is three! Let's analyze the code carefully to really understand what's going on.
First, an Int32 unboxed value type (v) is created and initialized to 5. Then an Object reference type (o) is created and it wants to point to v. But reference types must always point to objects in the heap, so C# generated the proper IL code to box v and stored the address of the boxed version of v in o. Now 123 is unboxed and the referenced data is copied into the unboxed value type v; this has no effect on the boxed version of v, so the boxed version keeps its value of 5. Note that this example shows how o is unboxed (which returns a pointer to the data in o), and then the data in o is memory copied to the unboxed value type v.
Now, you have the call to WriteLine. WriteLine wants a String object passed to it but you don't have a String object. Instead, you have these three items: an Int32 unboxed value type (v), a string, and an Int32 reference (or boxed) type (o). These must somehow be combined to create a String.
To accomplish this, the C# compiler generates code that calls the String object's static Concat method. There are several overloaded versions of Concat. All of them perform identically; the difference is in the number of parameters. Since you want to format a string from three items, the compiler chooses the following version of the Concat method:
public static String Concat(Object arg0, Object arg1, Object arg2);
For the first parameter, arg0, v is passed. But v is an unboxed value parameter and arg0 is an Object, so v must be boxed and the address to the boxed v is passed for arg0. For the arg1 parameter, the address of the ", " string is passed, identifying the address of a String object. Finally, for the arg2 parameter, o (a reference to an Object) was cast to an Int32. This creates a temporary Int32 value type that receives the unboxed version of the value currently referred to by o. This temporary Int32 value type must be boxed once again with the memory address being passed for Concat's arg2 parameter.
Once Concat is called, it calls each of the specified object's ToString methods and concatenates each object's string representation. The String object returned from Concat is then passed to WriteLine to show the final result.
I should point out that the generated IL code would be more efficient if the call to WriteLine were written as follows:
Console.WriteLine(v + ", " + o); // Displays "123, 5"
This line is identical to the previous version except that I've removed the (Int32) cast that preceded the variable o. This code is more efficient because o is already a reference type to an Object and its address may simply be passed to the Concat method. So, removing the cast saved both an unbox and a box operation.
Here is another example that demonstrates boxing and unboxing:
public static void Main() {
Int32 v = 5; // Create an unboxed value type variable
Object o = v; // o refers to the boxed version of v
v = 123; // Changes the unboxed value type to 123
Console.WriteLine(v); // Displays "123"
v = (Int32) o; // Unboxes o into v
Console.WriteLine(v); // Displays "5"
}
How many boxing operations do you count in this code? The answer is one. There is only one boxing operation because there is a WriteLine method that accepts an Int32 as a parameter:
public static void WriteLine(Int32 value);
In the two calls to WriteLine, the variable v (an Int32 unboxed value type) is passed by value. Now, it may be that WriteLine will box this Int32 internally, but you have no control over that. The important thing is that you've done the best you could and have eliminated the boxing from your code.
If you know that the code you're writing is going to cause the compiler to generate a lot of boxing code, you will get smaller and faster code if you manually box value types, as shown in Figure 4.
The C# compiler automatically generates boxing and unboxing code. This makes programming easier, but it hides the overhead from the programmer who is concerned with performance. Like C#, other languages may also hide boxing or unboxing details. However, some languages may force the programmer to explicitly write boxing or unboxing code. For example, C++ with Managed Extensions requires that the programmer explicitly box value types using the __box operator; unboxing a value type is done by casting the boxed type to its unboxed equivalent using dynamic_cast.
One last note: if a value type doesn't override a virtual method defined by System.ValueType, then this method can only be called on the boxed form of the value type. This is because only the boxed form of the object has a pointer to a virtual method table. Methods defined directly with the value type can be called on boxed and unboxed versions of the value.
Casting Continues....(Test ur Casting Skiils!!)
To make sure you understand everything presented in previous article, assume that the following two class definitions exist.
class B {
int x;
}
class D : B {
int x;
}
ES: Execute Successfully
CE: Compiler Error
RE: Runtime Error
Statement ES CE RE
System.Object o1 = new System.Object(); Y N N
System.Object o2 = new B(); Y N N
System.Object o3 = new D(); Y N N
System.Object o4 = o3; Y N N
B b1 = new B(); Y N N
B b2 = new D(); Y N N
D d1 = new D(); Y N N
B b3 = new System.Object(); N Y N
D d3 = new System.Object(); N Y N
B b3 = d1; Y N N
D d2 = b2; N Y N
D d4 = (D) d1; Y N N
D d5 = (D) b2; Y N N
D d6 = (D) b1; N N Y
B b4 = (B) o1; N N Y
B b5 = (D) b2; Y N N
class B {
int x;
}
class D : B {
int x;
}
ES: Execute Successfully
CE: Compiler Error
RE: Runtime Error
Statement ES CE RE
System.Object o1 = new System.Object(); Y N N
System.Object o2 = new B(); Y N N
System.Object o3 = new D(); Y N N
System.Object o4 = o3; Y N N
B b1 = new B(); Y N N
B b2 = new D(); Y N N
D d1 = new D(); Y N N
B b3 = new System.Object(); N Y N
D d3 = new System.Object(); N Y N
B b3 = d1; Y N N
D d2 = b2; N Y N
D d4 = (D) d1; Y N N
D d5 = (D) b2; Y N N
D d6 = (D) b1; N N Y
B b4 = (B) o1; N N Y
B b5 = (D) b2; Y N N
Monday, April 25, 2005
Implicit Casting / Explicit Casting / "as" Operator / "is" Operator
Let see them in action :
1. Implicit Casting
When programming, it is quite common to cast an object from one data type to another. In this section, I'll look at the rules that govern how objects are cast between data types. To start, look at the following line:
System.Object o = new Jeff("ConstructorParam1");
The previous line of code compiles and executes correctly because there is an implied cast. The new operator returns a reference to a Jeff type, but o is a reference to a System.Object type. Since all types (including the Jeff type) can be cast to System.Object, the implied cast is successful.
2. Explicit Casting
However, if you execute the following line, you get a compiler error since the compiler does not provide an implicit cast from a base type to a derived type.
Jeff j = o;
To get the command to compile, you must insert an explicit cast, as follows:
Jeff j = (Jeff) o;
Now the code compiles and executes successfully.
Let's look at another example:
System.Object o = new System.Object();
Jeff j = (Jeff) o;
On the first line, I have created an object of type System.Object. On the second line, I am attempting to convert a reference of type System.Object to a reference of type Jeff. Both lines of code compile just fine. However, when executed, the second line generates an InvalidCastException exception, which if not caught, forces the application to terminate.
When the second line of code executes, the common language runtime verifies that the object referred to by o is in fact an object of type Jeff (or any type derived from type Jeff). If so, the common language runtime allows the cast. However, if the object referenced by o has no relationship to Jeff, or is a base class of Jeff, then the common language runtime prevents the unsafe cast and raises the InvalidCastException exception.
3. as Operator
C# offers another way to perform a cast using the as operator:
Jeff j = new Jeff(); // Create a new Jeff object
System.Object o = j as System.Object; // Casts j to an object
// o now refers to the Jeff object
The as operator attempts to cast an object to the specified type. However, unlike normal casting, the as operator will never throw an exception. Instead, if the object's type cannot be cast successfully, then the result is null. When the ill-cast reference is used, a NullReferenceException exception will be thrown. The following code demonstrates this concept.
System.Object o = new System.Object(); //Creates a new Object object
Jeff j = o as Jeff; //Casts o to a Jeff
// The cast above fails: no exception is raised but j is set to null
j.ToString(); // Accessing j generates a NullReferenceException
Here comes the Final Rescue !!
4. is Operator
In addition to the as operator, C# also offers an is operator. The is operator checks whether an object instance is compatible with a given type and the result of the evaluation is either True or False. The is operator will never raise an exception.
System.Object o = new System.Object();
System.Boolean b1 = (o is System.Object); // b1 is True
System.Boolean b2 = (o is Jeff); // b2 is False
Note, if the object reference is null, the is operator always returns False since there is no object available to check its type.
That's all i can say ...Happy Casting !!
Regards,
Deepak
1. Implicit Casting
When programming, it is quite common to cast an object from one data type to another. In this section, I'll look at the rules that govern how objects are cast between data types. To start, look at the following line:
System.Object o = new Jeff("ConstructorParam1");
The previous line of code compiles and executes correctly because there is an implied cast. The new operator returns a reference to a Jeff type, but o is a reference to a System.Object type. Since all types (including the Jeff type) can be cast to System.Object, the implied cast is successful.
2. Explicit Casting
However, if you execute the following line, you get a compiler error since the compiler does not provide an implicit cast from a base type to a derived type.
Jeff j = o;
To get the command to compile, you must insert an explicit cast, as follows:
Jeff j = (Jeff) o;
Now the code compiles and executes successfully.
Let's look at another example:
System.Object o = new System.Object();
Jeff j = (Jeff) o;
On the first line, I have created an object of type System.Object. On the second line, I am attempting to convert a reference of type System.Object to a reference of type Jeff. Both lines of code compile just fine. However, when executed, the second line generates an InvalidCastException exception, which if not caught, forces the application to terminate.
When the second line of code executes, the common language runtime verifies that the object referred to by o is in fact an object of type Jeff (or any type derived from type Jeff). If so, the common language runtime allows the cast. However, if the object referenced by o has no relationship to Jeff, or is a base class of Jeff, then the common language runtime prevents the unsafe cast and raises the InvalidCastException exception.
3. as Operator
C# offers another way to perform a cast using the as operator:
Jeff j = new Jeff(); // Create a new Jeff object
System.Object o = j as System.Object; // Casts j to an object
// o now refers to the Jeff object
The as operator attempts to cast an object to the specified type. However, unlike normal casting, the as operator will never throw an exception. Instead, if the object's type cannot be cast successfully, then the result is null. When the ill-cast reference is used, a NullReferenceException exception will be thrown. The following code demonstrates this concept.
System.Object o = new System.Object(); //Creates a new Object object
Jeff j = o as Jeff; //Casts o to a Jeff
// The cast above fails: no exception is raised but j is set to null
j.ToString(); // Accessing j generates a NullReferenceException
Here comes the Final Rescue !!
4. is Operator
In addition to the as operator, C# also offers an is operator. The is operator checks whether an object instance is compatible with a given type and the result of the evaluation is either True or False. The is operator will never raise an exception.
System.Object o = new System.Object();
System.Boolean b1 = (o is System.Object); // b1 is True
System.Boolean b2 = (o is Jeff); // b2 is False
Note, if the object reference is null, the is operator always returns False since there is no object available to check its type.
That's all i can say ...Happy Casting !!
Regards,
Deepak
Garbage Collection in .NET + Weak References
Best article on Gabage Collection i have ever seen on the earth !!
Apart from Garbage collection it also tell u about Weak References...
Weak references are a means of performance enhancement, used to reduce the pressure placed on the managed heap by large objects.
When a root points to an abject it's called a strong reference to the object and the object cannot be collected because the application's code can reach the object.
When an object has a weak reference to it, it basically means that if there is a memory requirement & the garbage collector runs, the object can be collected and when the application later attempts to access the object, the access will fail. On the other hand, to access a weakly referenced object, the application must obtain a strong reference to the object. If the application obtains this strong reference before the garbage collector collects the object, then the GC cannot collect the object because a strong reference to the object exists.
http://www.codeproject.com/dotnet/garbagecollection.asp
To support this article, we have another article by our Windows Guru Jeffery Richter
http://msdn.microsoft.com/msdnmag/issues/1200/GCI2/default.aspx
Sample Code for Weak References:
Void Method() {
Object o = new Object(); // Creates a strong reference to the
// object.
// Create a strong reference to a short WeakReference object.
// The WeakReference object tracks the Object.
WeakReference wr = new WeakReference(o);
o = null; // Remove the strong reference to the object
o = wr.Target;
if (o == null) {
// A GC occurred and Object was reclaimed.
} else {
// a GC did not occur and we can successfully access the Object
// using o
}
Bye for Now..Will come again !!
Apart from Garbage collection it also tell u about Weak References...
Weak references are a means of performance enhancement, used to reduce the pressure placed on the managed heap by large objects.
When a root points to an abject it's called a strong reference to the object and the object cannot be collected because the application's code can reach the object.
When an object has a weak reference to it, it basically means that if there is a memory requirement & the garbage collector runs, the object can be collected and when the application later attempts to access the object, the access will fail. On the other hand, to access a weakly referenced object, the application must obtain a strong reference to the object. If the application obtains this strong reference before the garbage collector collects the object, then the GC cannot collect the object because a strong reference to the object exists.
http://www.codeproject.com/dotnet/garbagecollection.asp
To support this article, we have another article by our Windows Guru Jeffery Richter
http://msdn.microsoft.com/msdnmag/issues/1200/GCI2/default.aspx
Sample Code for Weak References:
Void Method() {
Object o = new Object(); // Creates a strong reference to the
// object.
// Create a strong reference to a short WeakReference object.
// The WeakReference object tracks the Object.
WeakReference wr = new WeakReference(o);
o = null; // Remove the strong reference to the object
o = wr.Target;
if (o == null) {
// A GC occurred and Object was reclaimed.
} else {
// a GC did not occur and we can successfully access the Object
// using o
}
Bye for Now..Will come again !!
Thursday, April 14, 2005
.NET Questions Bank - Good Collection
http://groups.msn.com/MumbaiUserGroup/netinterviewquestions.msnw
Subscribe to:
Comments (Atom)